
|
Un processo Ķ normalmente considerato come un programma in elaborazione con un unico flusso di esecuzione delle istruzioni (percorso di controllo), che pu“ variare al seconda dei dati in ingresso forniti a tale processo. Molti sistemi operativi moderni permettono che un processo possa avere pi∙ percorsi di controllo che comunemente si chiamano thread. A un processo, sono associati i seguenti dati e le seguenti informazioni: il codice del programma in esecuzione, unÆarea di memoria contenente le strutture dati dichiarate nel programma in esecuzione, i file aperti, lo stack (per le chiamate di procedure e funzioni, variabili locali ecc..) e il contenuto dei registri della CPU. Consideriamo due processi che devono lavorare sugli stessi dati. Come possono fare, se ogni processo ha la propria area dati? I dati potrebbero essere scambiati mediante messaggi o tenuti in memoria condivisa oppure possono essere tenuti in un file che viene acceduto a turno dai due processi. Sarebbe per“ molto pi∙ comodo poter avere processi che possano automaticamente lavorare sugli stessi dati, considerando anche che il cambiamento di contesto tra processi richiede molto lavoro al SO che oltre a cambiare il valore dei vari registri, deve spostarsi dalle aree dati e di codice del processo uscente, a quelle del processo entrante. Ad esempio, in un editor di testo un processo gestisce lÆinput e i comandi di formattazione dellÆutente e un altro processo esegue il controllo automatico di errore. I due processi dovrebbero lavorare sullo stesso testo e la copia corrente del testo Ķ mantenuta in memoria principale. Come fanno i due processi a condividere la stessa copia, se ogni processo ha un diverso spazio di indirizzamento? Per soddisfare questo tipo di esigenza Ķ nato il concetto di thread. Un normale processo Ķ contraddistinto da un unico Thread (filo) di computazione: la sequenza di istruzioni eseguite (che ovviamente pu“ cambiare da unÆesecuzione allÆaltra, se cambiano, ad esempio, i dati di input).
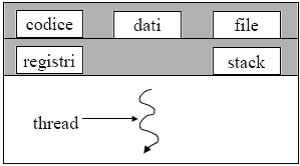
Un processo Multi-Thread Ķ fatto di pi∙ thread, detti peer thread. Un insieme dei peer thread Ķ detto task.
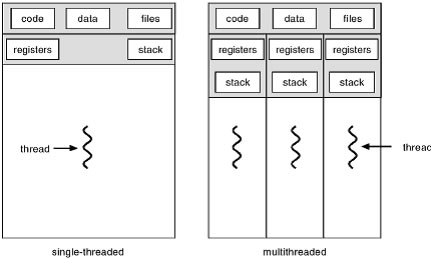
Ad ogni thread Ķ associato in modo esclusivo il suo stato della computazione, fatto dal valore del program counter e degli altri registri della CPU e da uno stack. Il thread condivide con i suoi peer thread il codice in esecuzione, i dati e i file aperti. Condividendo gli stessi dati e quindi lo stesso spazio di indirizzamento, i thread di uno stesso task vedono le stesse variabili: se uno dei thread modifica una variabile, la modifica Ķ vista anche dagli altri thread. I context switch avviene anche tra ognuno dei peer thread che formano task, in modo che tutti possano portare avanti la computazione. Ma il context switch fra peer thread richiede il salvataggio e il ripristino solo dei registri della CPU e dello stack (che sono diversi per ogni thread). Codice, dati e file aperti sono gli stessi per tutti, e non devono essere cambiati di conseguenza il context switch tra thread Ķ molto pi∙ veloce. Per questa ragione, i normali processi sono spesso chiamati heavy-weight process (HWP), mentre per un singolo thread Ķ usato spesso il termine light-weight process (LWP). Ma come si fa a distinguere tra i thread di un task (in modo da far fare a ciascuno una cosa diversa), se questi condividono lo stesso codice? Si utilizzano delle opportune system call, che allÆinterno del codice permettono di creare i thread necessari, e specificano per ciascun thread quale pezzo di codice deve eseguire quel thread. Naturalmente, altre system call permetteranno ai thread di sincronizzarsi fra di loro. Si possono utilizzare diverse politiche di scheduling per distribuire il tempo di CPU fra in vari peer thread allÆinterno di un task, e tra i thread appartenenti a task diversi. Uno stesso sistema operativo, pu“ anche permettere allÆutente di specificare la politica di scheduling preferita per le proprie applicazioni che utilizzino i thread. Si pu“ avere quindi uno: Scheduling Thread a livello utente (user-level thread): Il SO non ōsaö dellÆesistenza dei threads. Si dice che i thread esistono solo a livello utente. Il context switch da un peer thread allÆaltro (allÆinterno quindi dello stesso task) avviene mediante opportune funzioni di libreria chiamate allÆinterno del codice dei thread stessi. Quando un thread sta per fermarsi, specifica prima quale peer thread deve proseguire la computazione. Il SO vede un task fatto di pi∙ thread come un normale processo, e gli assegna la CPU secondo il criterio di scheduling adottato per lÆintero sistema. Scheduling Thread a livello kernel (kernel-level thread): Il SO deve mantere delle strutture dati per gestire sia i normali processi che tutti i peer thread di un task. Quando un thread si blocca volontariamente, o termina il suo quanto di tempo, Ķ il SO che assegna la CPU a un altro thread dello stesso task, o a un altro thread di un altro task o a un altro processo normale. Quindi il SO gestisce ogni singolo thread secondo il modello time-sharing. In conclusione i vantaggi dellÆ uso dei thread sono:
Efficienza: creare un LWP richiede circa 30 volte meno tempo che creare un HWP. Il context switch tra peer thread richiede 5 volte meno tempo del context switch tra processi.
Condivisione di dati e risorse: pi∙ thread possono lavorare su dati condivisi in maniera efficiente (ma devono sincronizzarsi in maniera adeguata)
Uso di architetture con pi∙ CPU: i thread sono naturalmente adatti per lavorare in parallelo su pi∙ CPU che condividono la stessa principale.
Tutto quanto riportato in questa pagina Ķ a puro scopo informativo personale. Se non ti trovi in accordo con quanto riportato nella pagina, vuoi fare delle precisazioni, vuoi fare delle aggiunte o hai delle proposte e dei consigli da dare, puoi farlo mandando un email. Ogni indicazione Ķ fondamentale per la continua crescita del sito.